db2Dean a.k.a. Dean Compher a.k.a “The Dean of DB2” is here to answer your DB2 Questions !
|
Utah Events None currently Scheduled
Nevada Events None currently Scheduled
|
See my Github Repo:
|
|
|
Online Events
Other Events
|

Welcome to db2Dean’s web site. I’m Dean Compher an IBM IT Specialist who, along with my team, helps customers and prospective customers with Cloud Pak for Data and DB2 on Linux, UNIX and Windows (LUW) technical questions and issues. As this page makes painfully clear, I am a DBA and not a web designer, but I would be happy to get your DB2 questions answered or talk to you about the great features of DB2 or IBM Integration Products. If you are looking at a new database solution or want to compare us to your existing database vendor, please do not hesitate to contact me about getting a presentation or just to ask questions. My e-mail address is dean@db2Dean.com
I am located in Utah and primarily serve CPD and DB2/LUW customers in the Western US, but I can forward requests to my peers in other technology and geographic areas as well. My team also covers Big Data and Informix and products. There are questions that I get on a regular basis, and I will write articles relating to them here. I hope that you find them useful. I also welcome suggestions for future content. Click here for more information about me.
|
|
16 October 2023 Dean Compher
There are a number of stored procedures that come with Db2 that are made for working with machine learning models, but can be used for run of the mill database administration in Db2. These procedures do things like give you information about columns in your tables including maximum and minimum values, number of null values in each column and other statistical information. There is also one that makes it easy to randomly copy rows form one table into two other tables. In this article I’ll describe how to get started and show some examples of using these functions.
Getting Started.
If you are running Db2 Warehouse or Db2 Warehouse on Cloud, these procedures are already deployed for you, but if you are running regular Db2 software, then you need to run a few tasks to implement the functions. See the Prerequisites for machine learning in Db2 page for the implementation steps. I did run into one issue when running the command that installs the procedures and got the error shown here:
$ db2updv115 -a -d sample
Error dropping module component with stmt: DROP MODULE SYSIBMADM.DBMS_UTILITY SQLCA: SQL0478N The statement failed because one or more dependencies exist on the target object. Target object type: "MODULE". Name of an object that is dependent on the target object: "DB2INST1.LAST_NAME". Type of object that is dependent on the target object: "MASK". LINE NUMBER=1. SQLSTATE=42893
This error indicates that I had column masks that prevented the utility from running. I dropped all the column masks in the database and ran the command again and it was successful. After this all steps worked well.
In the following sections I will provide examples of a few procedures I found to be the most interesting, but you can read about all of the Db2 traditional install procedures on the Machine learning stored procedure page. Db2 Warehouse and Db2 Warehouse on Cloud have quite a few additional stored procedures and you can read about them on the Analytic stored procedures page. You should note that to use these functions your Db2 user will need the authority to crate tables since they put their output in one or more tables that that are created during execution.
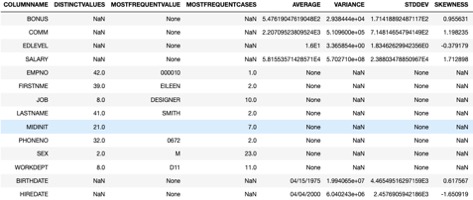
Column Statistics The IDAX.SUMMARY1000 procedure gives lots of interesting statistics about the data in your columns for a particular table. You can specify individual columns that interest you or just let the procedure gather information on all the columns in the table up to a maximum of 1000 columns. For columns of all data types it will show you the count of null values (missing values) and not null values. For character columns it also shows the number of distinct values and the most frequent value. For numeric columns it shows statistical information including max value, min value, average value, standard deviation, and other interesting information.
When you run the stored procedure, it will create a few tables that hold the output of the function. One will be created that shows the information for all columns and one will be created for each unique data type among your columns. Each of those tables will have a suffix corresponding to the data type. The data type specific tables show just the columns of that data type. Each time you run the procedure you need to drop the tables created in the previous run or the procedure will fail. Example 1 shows he queries I ran to get information for the EMPLOYEE table and a portion of the output of the primary output table.
Example 1. IDAX.SUMMARY1000
drop table if exists DEAN.EMPLOYEE_SUM1000; drop table if exists DEAN.EMPLOYEE_SUM1000_CHAR; drop table if exists DEAN.EMPLOYEE_SUM1000_NUM; drop table if exists DEAN.EMPLOYEE_SUM1000_TIMESTAMP; drop table if exists DEAN.EMPLOYEE_SUM1000_DATE; CALL IDAX.SUMMARY1000('intable=DB2INST1.EMPLOYEE, outtable=DEAN.EMPLOYEE_SUM1000');
select * from dean.EMPLOYEE_SUM1000;
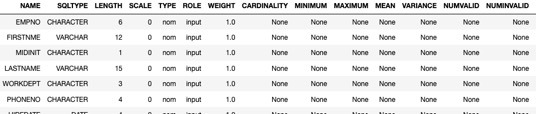
Column Properties The IDAX.COLUMN_PROPERTIES procedure gives some interesting information about the definitions of the columns for a particular table. You can specify individual columns that interest you or just let the procedure gather information on all the columns.
When you run the stored procedure, it will create a table that holds the output of the function. You then query that table to see the information. Each time you run the procedure you need to drop the table created in the previous run or the procedure will fail. Example 2 shows he queries I ran to get information for the EMPLOYEE table and a portion of the information on the columns.
Example 2. IDAX.COLUMN_PROPERTIES
drop table if exists DEAN.EMPLOYEE_COL_INFO; call IDAX.COLUMN_PROPERTIES('intable=DB2INST1.EMPLOYEE, outtable=DEAN.EMPLOYEE_COL_INFO');
select * from DEAN.EMPLOYEE_COL_INFO;
Create 2 Partial Copies The IDAX.SPLIT_DATA procedure creates two tables identical to one that exists in the database and randomly copies rows from the original table to one of the two tables. You specify the percentage of rows to be copied to the “training” table and the rest are copied to the “test” table. You can also specify the seed for the random numbers and the percentage in decimal form using the “fraction” parameter. This function is typically used to create two sets of data for machine learning model development – one to train it and the other to see how well it performs on data unseen during training. I can see other use cases such as when you need a random sample of data for testing or other experimental purposes. In that case you could create the tables and drop the one you don’t need. Example 3 shows creating a 60-40 split of the employee table.
Example 2. IDAX.SPLIT_DATA
DROP TABLE IF EXISTS DEAN.EMPLOYEE_TRAIN60; DROP TABLE IF EXISTS DEAN.EMPLOYEE_TEST40; CALL IDAX.SPLIT_DATA('intable=DB2INST1.EMPLOYEE, id=EMPNO, traintable=DEAN.EMPLOYEE_TRAIN60, testtable=DEAN.EMPLOYEE_TEST40, fraction=0.6, seed=1');
select 'EMPLOYEE SOURCE COUNT', count(*) from db2inst1.EMPLOYEE UNION All select '40% COUNT', count(*) from db2inst1.EMPLOYEE_TEST40 UNION All select '60% COUNT', count(*) from db2inst1.EMPLOYEE_TRAIN60
Other Procedures There are other procedures that you may also find useful like the IDAX.IMPUTE_DATA procedure that replaces null values with “typical” values such as the most frequent value, or “statistically useful” value such as mean or median values of the column. Also, there is the IDAX.STD_NORM procedure that can add columns with normalized or standardized values. Neither of these procedures change the source table, but instead create a new table with the changes you desire. There are several other functions that may be useful as well that you can browse on the Machine learning stored procedure page.
|
Db2Dean’s Other Interests
|