Db2, Lakehouse, and watsonx.data
27 June 2023
Dean Compher
Db2 is participating in two large trends, namely the ability to put various data sets where they get the best cost/performance tradeoff and the ability to separate compute from storage. In this article I will discuss these trends and then talk about how Db2 is supporting them.
Put Data where you get best cost/performance tradeoff
The idea here is that not all data has the same value per byte. For example, transactions captured in your systems in the last 6 months are probably more valuable than transaction data that is 2 years old and that data is more valuable than 10-year-old transaction data. This is because newer data tends to be used by higher value applications that run your business than old data. Another example is where data for your core business systems is more valuable than data for systems that you could do without in a pinch. Because different sets of data have different values per byte, it would make sense to put data sets on the least expensive storage that provided adequate performance for the way you want to use it, especially when you have huge volumes of lesser value data. In the past, the lessor value data would likely have been deleted or archived off-line, but with newer technologies, you can afford to keep old data for things like historical analysis and training machine learning models.
One of the things enabling this is the advent of extremely low-cost cloud object storage that also has pretty good performance. This type of storage is provided by Amazon Web Services, IBM Cloud and others. The most widely used way to interact with this storage is the S3 Standard. AWS created the standard and their cloud object S3 storage service is probably the best known. However, other cloud providers use this standard and you can even use it to connect to a number of on-premises storage systems using open source software such as Ceph or MinIO. In addition to cloud object storage there are other ways to get more inexpensive storage such as with Hadoop clusters.
There are various cases driving this trend, but they all revolve around storing enormous amounts of data as cheaply as possibly while getting easy and relatively fast access to it. Here are a couple of examples:
· Artificial Intelligence – In general terms, the more data you can keep for training your AI models the more accurate and precise your predictions will be. This is true for Large Language Models like that used by ChatGPT or to do more mundane machine learning models that can do things like score the probability that your internet user is who they say they are.
· I might need that – Many databases are clogged with old data that the owners won’t give permission to delete (not yours, of course). It would be great to continue to allow access but keep that old data in inexpensive storage.
Separation of Compute and Storage
This trend is primarily being driven by cloud computing but is also applicable to on-premises and hybrid systems too. I see three different aspects of this trend:
1. Cloud computing is like the power connected to your home – each additional unit you consume adds to your bill at the end of the month. With databases the amount of storage you consume tends to be somewhat stable and growing at some rate. However, the amount of CPU and RAM you need at any given moment can vary wildly, depending the query load and you may not even need any at night if no users are connected. So being able to scale down the compute resources you are using or even turn it off can save money while providing adequate performance for peak loads.
2. Within the same database it is desirable to store different classes of data on different classes of storage to get the best cost/performance for a class of data as discussed above. In the cloud world this trade-off is typically between more expensive and better performing block storage vs. object storage. Previously, databases tended to have only one type of storage for the engine, but with the separation, the engine can use any type of storage.
3. Store data in some open format such as Parquet or CSV, and allow any query engine whether SQL based or not to access the data files directly. For example, if you have Parquet files in Amazon S3 you may want to be able to see it as a table in your Db2 database while also reading the files from a Spark application or query it from an open source Presto engine. In this case you have one copy of the data, but you can use a variety of different compute engines.
How does Db2 Play
There are two different ways that Db2 Warehouse and Db2 Warehouse on Cloud will participate. One way that I will explore in a later article is by creating tablespaces on object storage. In this article I will explore Db2 Warehouse’s interaction with the IBM watsonx.data Lakehouse. For now, Db2 Warehouse and Db2 Warehouse on Cloud are the only Db2 offerings that will have this ability. Also, some of the features I mention here will not be available in the initial release.
At the Think Conference in May, IBM announced the IBM watsonx.data Lakehouse. Db2 Warehouse and Netezza are getting new features where you can create Db2 tables on files/tables in the Lakehouse. The Lakehouse can also connect to Db2 and Netezza and query data in the traditionally stored tables in those databases. This means that you can use either the Db2 Warehouse or watsonx.data engines to query any tables owned by either engine. The capabilities I discuss in the rest of the articles for Db2 Warehouse also apply to Netezza.
What is the watsonx.data Lakehouse? That’s a pretty big topic, but I will attempt to summarize that here. This description is only meant to give you a very high-level understanding of what it is. There is much more to it that you can read about in the watsonx.data site. It is made up of a number of open-source tools, combined in such a way that they provide an easy way to store data in open formats and query it along with some added tooling from IBM to make them easy to administer. The first is a combination Iceberg and Hive to provide a catalog also known as a metadata store. Just as the Db2 catalog tables enable queries by keeping information about tables, columns and data types, underlying storage for the tables and tablespaces, etc., the watsonx.data catalog does this for files stored in S3 storage in formats like Parquet. This catalog (metadata store) is also a service that can be queried and updated by other applications. It will also keep connection information to other databases like Postgres and allow you to catalog tables in this catalog that physically exist in another database and not in files on S3 Storage.
The next major component is the Presto engine. IBM is using the Ahana distribution of the open-source Presto engine. You can think of Presto as doing a similar function as any other database engine like Db2, Oracle, Postgres, etc. It is a process running on a server somewhere and applications connect to it using a JDBC driver to submit SQL queries and get back result sets. It also provides administrative tools like other databases do to create tables, test queries and administer the engine. When you create a table using Presto it stores the table definition, including storage information like file name and file format (say Parquet) in the catalog (metadata service). When Presto executes a query, it gets the table definition and location information from the catalog and then reads the file(s) and presents the results to the client. You can SELECT and INSERT tables using a connection to Presto. Since the data is in files that can’t be changed, inserts to an existing table are added in additional files in the same object store bucket (a.k.a directory). This allows you to query data as of various points in time. When deploying watsonx.data (either as a cloud service or on your own infrastructure) you can optionally also install a Spark engine.
Since the files are in open-source formats like Parquet any application that has the credentials to connect to the object store can read and process those files directly. Further, since the catalog is in open-source Iceberg/Hive any query engine including Db2 Warehouse can query the metadata service to determine table format and location, and then read the files to provide query results. This means that you aren’t locked into watsonx.data. If you ever decide that it isn’t for you, all your data is still available without changes because it’s in an open format in object storage, plus if your new query tool can talk to Iceberg and Hive then it can see the files as tables to be queried by SQL.
Db2 Warehouse is getting features that allow you to synchronize the watsonx.data catalog with their catalogs. This means that when you configure it to talk to watsonx.data it can see the tables defined to Iceberg and those tables can be made available to the users of the Db2 Warehouse database. When this is done, applications connected to Db2 Warehouse can see the local tables as well as the watsonx.data tables. Local tables can be joined with watsonx.data tables. The applications will not be able to tell the difference. This provides you with the ability to put your data where you get the best cost/performance tradeoff for the particular set of data while accessing everything through your awesome Db2 Warehouse data warehouse.
An example of how you might use that is archiving old data in your Db2 Warehouse while still having easy access. You could create a local table in Db2 to hold some sort of data rows less than two years old that are quite valuable and need the fastest access, but older rows, while still being useful for historical analysis don’t need the fastest access. In this case you could create another table that looks just like the original but created on watsonx.data. Now your applications can query just the local table, just the remote table or join the tables using a UNION ALL query. Further, applications that need just the older data can read it without adding any load to Db2 Warehouse because those applications can query the data through the Presto engine or even read the files directly.
As I noted earlier, you can create tables in watsonx.data that are actually tables in other databases. You just define the credentials for the Db2 database to watsonx.data metadata service. These table definitions are placed in the watsonx.data catalog, but instead of pointing to files in object storage, they point to tables in Db2. This is very similar to creating federated tables in Db2 or Fluid Query in Netezza that point to tables outside of those databases. Now you can query tables from any query engine whether stored in files in object storage or in Db2, Netezza or other databases.
So with these capabilities, Db2 Warehouse allows for both storing data where it is most efficient and separate compute from storage by allowing to pick the engine for accessing the data that you prefer or keeping the data active while scaling the Db2 Warehouse engine up or down.
This diagram by Herb Pereyra that shows how the components fit together.
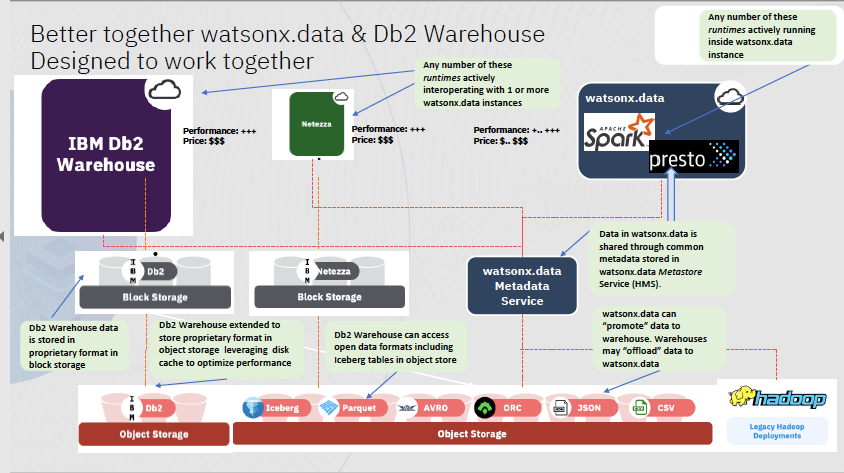
***
As of the date of this article, these features are not yet available, but the features will be released starting in July and throughout the year. Please feel free to share any thought you have on this on my Facebook Page.