Apache Spark & Data Scientist Workbench:
A simplified way to obtain insight from your Big Data
Anjali Khatri & Maria N Schwenger
28 August 2015
Updated 31 August 2015 (First 2 Pages Only)
Apache® SparkTM (Spark) is an open source cluster computing platform that was developed in 2009 at the AMPLab at UC Berkeley. Compared to the traditional Hadoop®’s MapReduce capability, Spark was designed to provide from 10 to 100 times faster performance for specific applications. While in the traditional Hadoop environment(s), high volumes of data can be processed by using analytical components such as Hive or HBase with MapReduce as an underlying processing engine, in Spark, the querying is done in-memory where real-time or archived data can provide faster time-to-value results. Spark complements Hadoop’s capabilities by providing a unified platform for storing and analyzing the data in a single environment.
Over the years, Spark has gained over 450 contributors, which have made it one of the most active Apache projects. Most of its contributors are data scientists and developers from various companies, but anyone can submit patches, documentation and specific examples to the Spark project. IBM® has heavily invested into Apache Spark by providing its breakthrough systemML machine learning technology such as regression, clustering, filtering, reduction, extraction, optimization, etc. IBM has also committed to train one million Spark users and has opened the IBM Spark Technology Center in San Francisco to foster the development of the Spark community.
What people like about Spark is that it offers an integral view and opportunity to gain valuable insights by analyzing large volumes of structured and unstructured data. The main benefit is the capability to deliver these real-time insights based on a simplified software development process - creating and running algorithms to extract value from a wide range of data sets. Apache Spark is the platform for creating and running such algorithms. Many of its use cases are related to iterative machine learning algorithms and interactive analytics where it can accelerate results by reducing the time and effort required to write and execute the code. For industry specific needs, Spark can be utilized for its telematics, monitoring, detection and management capabilities, predictive, geo-mapping, social media analysis, etc. The Spark core is complemented by a set of powerful, higher-level libraries, which can be seamlessly used in a variety of applications. These libraries currently include SparkSQL, SparkR, Spark Streaming, MLlib, and GraphX. Spark can access and analyze data from Apache Hadoop and other data sources (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.), as well as enterprise data stores on-premise or in the cloud. You can run Spark either standalone or on clusters managed by Hadoop YARN or Apache Mesos.
Spark provides fast in-memory processing of resilient distributed datasets suitable for application or web logs, twitter streaming, weather time series and sensor applications, just to name a few.
Spark provides a simplified development environment because it leverages a variety of programming languages and libraries such as Python, Scala, SQL, R, NoSQL, etc. It is also easy to deploy multiple workloads in either machine learning or batch processing procedures.
IBM offers Spark on IBM’s Bluemix™ platform as a beta application for all users called Analytics for Apache Spark. Open source Spark can also be leveraged in IBM’s Hadoop distribution called the IBM Open Platform with Apache Hadoop. This distribution is based on the Open Data Platform (ODP) standard for its open source components.
One simplified way to explore the capabilities of IBM Spark is by using the web-based environment called the Data Scientist Workbench provided by IBM. It utilizes an interactive notebook experience and enables data scientists, data analysts, statisticians, etc. to interactively obtain insights from large volumes of data analyzed in Apache Spark.
The Data Scientist Workbench helps you query/search and navigate through data sets as you focus on data exploration, problem solving, and gaining deep data insights.
The workbench helps to address data exploration and interactive analytic needs in a cloud friendly manner by avoiding the hassle of downloads, application installations, or configurations.
With the workbench you can upload, transform, and explore large data sets with ease. You can reconcile and match your data by linking and extending your data sets with web services. The power of the interactive notebook environment provided in the workbench provides interactive data analytics. Using IPython/Jupyter notebooks you can control code execution, text, plots and rich media. You can utilize the pre-installed Python and R libraries or you can install others as needed. The best feature of the workbench is its simplicity, designed to allow everyone to get answers quickly. There are also extensive samples and how-to education provided by an active and growing community.
The Data Scientist Workbench provides a simplified and efficient way to utilize the newest technologies like Spark.
Next Steps
Follow step-by-step instructions on how to get IBM Spark hands-on experience using the IBM Data Scientist workbench.
Get started with Data Scientist Workbench
1) Setup Account
a) Go to https://www.datascientistworkbench.com from any web browser.

b) Navigate to the top of the page and click on Register. Submit the following form to request access to the workbench.
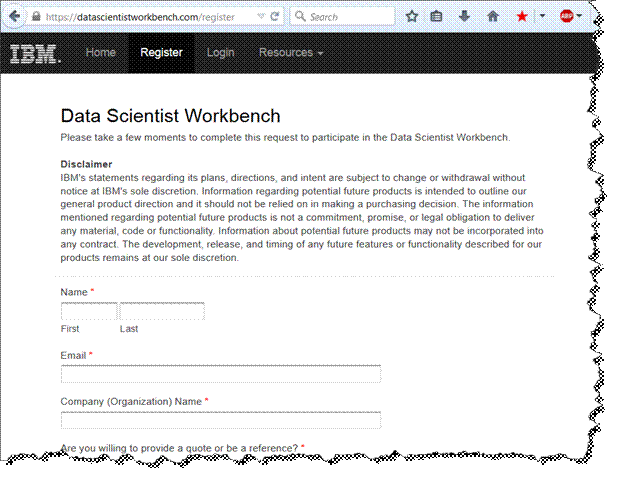
c) Within a few minutes of submiting the request, you will receive an email from “IBM Data Scientist Workbench” welcoming you to the platform. Click on the embedded link to verify account and setup password.
d) Once you have your credentials, navigate back to https://datascientistworkbench.com and click Login.
You are now ready to setup your workbench environment.

2) Setup your workbench environment
a) After you’ve logged into the workbench, navigate to My Notebooks.
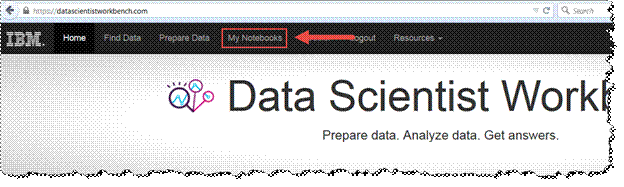
b) On the right of the screen, click on the blue dropdown box to select one of the programming languages. For this demonstration, we’ll be selecting Python 2.

c) With the selection of the language, a new workbook will be created and can be seen under “Recent Notebooks”.

d) Under “Recent Notebooks”, select the drop down for Untitled.ipynb and rename the workbook. For this demonstration, we’ll call it Testing.

3) Work with data set(s)
a) Once you’ve created the workbook, the next step is to upload a simple data set under Recent Data. For this demonstration, we are going to upload a .csv file. To upload, drag and drop the data file under Recent Data.

4) Display Data Sets
a) Once the data is uploaded, it can be seen within the Recent Data window.

5) Retrieve data by writing a simple query
a) Now that the notebook is created and a test dataset is uploaded to the workbench. We will execute a simple query to read the .csv file using Python.
· Pandas library is imported
· CSV file data is read using the panda library’s API called read_csv
· The variable test is ran to display results

b) To execute each of the following queries, you must click the run cell button.

c) After test is compiled, the following results display the contents of the CSV file.

Learn more about the Data Scientist Workbench
To get more information about the data scientist workbench, please go to the following link: https://developer.ibm.com/bluemix/tag/data-scientist-workbench/
Review Apache Spark Documentation
· Deep dive into the Apache Spark platform here: http://spark.apache.org/docs/latest
· Review the hands-on examples for Spark provided at: https://spark.apache.org/examples.html
Explore Apache Spark on Bluemix
To get hands on experience with Apache Spark using Jupyter, please go to IBM’s Bluemix http://bluemix.net and get hands on experience with IBM’s Spark initiative.