External Tables with Cloud Files
Dean Compher
27 January 2020
Using the cloud to store files has become quite common and it can be useful to query data in those files in-place using external tables in Db2. In Db2 you can create a table where the data is not stored in the database, but instead the table connects to the file and allows you to query it using SQL as you would with any other table. This can be useful when you want to explore a new file, but don’t want to take up storage in your tablespaces, or when you are just using it as a query source to load data into other tables. The data will typically need to be in delimited files such as CSV files, but I’ll also show examples here of using JSON files. In this article I discuss how create external tables referencing cloud storage with examples and show one way of connecting to cloud storage.
I’ll start by discussing how to connect your table to the files in the cloud and later show examples of using these external tables. If you’re like me and not all that familiar with cloud storage, figuring out where to put the various credentials from the cloud storage web site into your CREATE EXTERNAL TABLE command can be a challenge. While the create external table page has detailed instructions, the terms used there do not precisely match the terms used in the cloud storage web site. As of the writing of this article, you can use S3, SWIFT and Azure cloud storage. I used S3 on the IBM Cloud, so I’ll show examples of how I did it in hopes that it is helpful to you. If you wish to try it yourself, you can get free S3 storage at cloud.ibm.com where you can store enough data to try everything here. To get the free S3 storage space deploy the Lite plan of the Object Storage offering
Once you deploy your storage, you want to create a bucket. A bucket is like a directory where you store your files. The site walks you through creating a bucket and it is pretty easy. That’s the first thing you want to do. For my examples here I created a bucket called “external-table-cloud-bucket” and uploaded a file into that bucket called 'HOSPITAL_READMISSION_LOAD.csv'. Next, to be able to access files in that bucket you need to create a set of credentials to allow access from external applications like Db2. So, in the cloud object storage console in cloud.ibm.com, click “Service credentials” on the right and then the “New credential+” on the right:
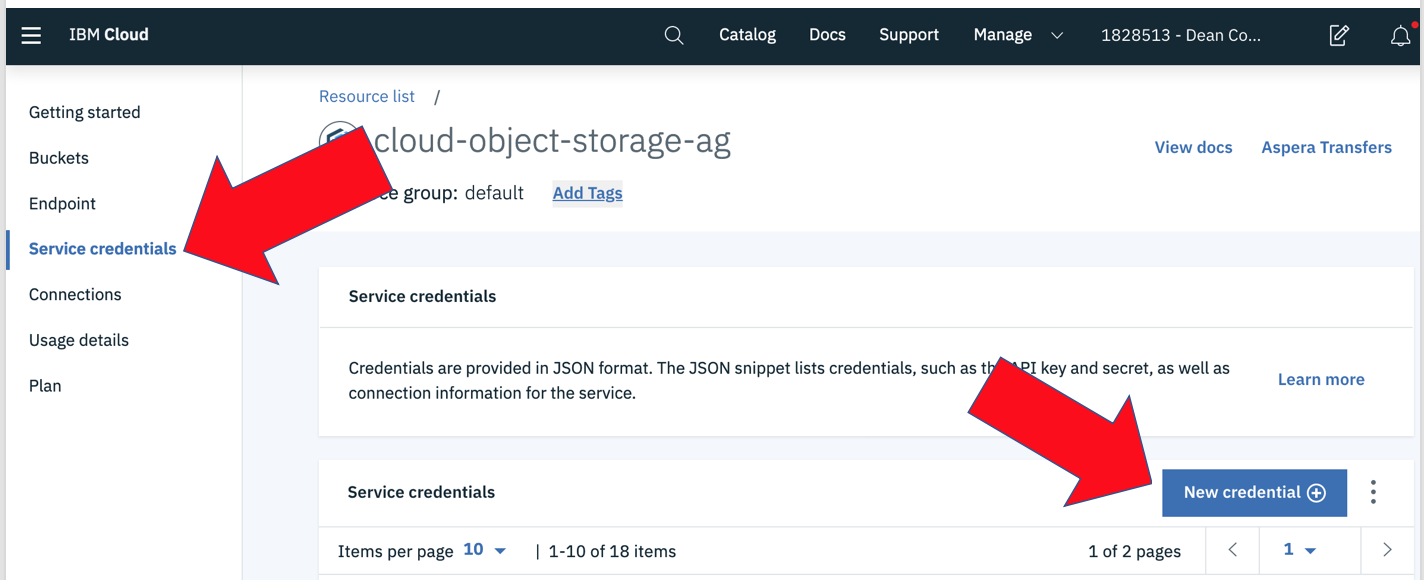
This starts the Add new credential window. For my purposes I named the credential “External_Table_Files” clicked the “Include HMAC Credential” and left defaults everywhere else and clicked the Add button.
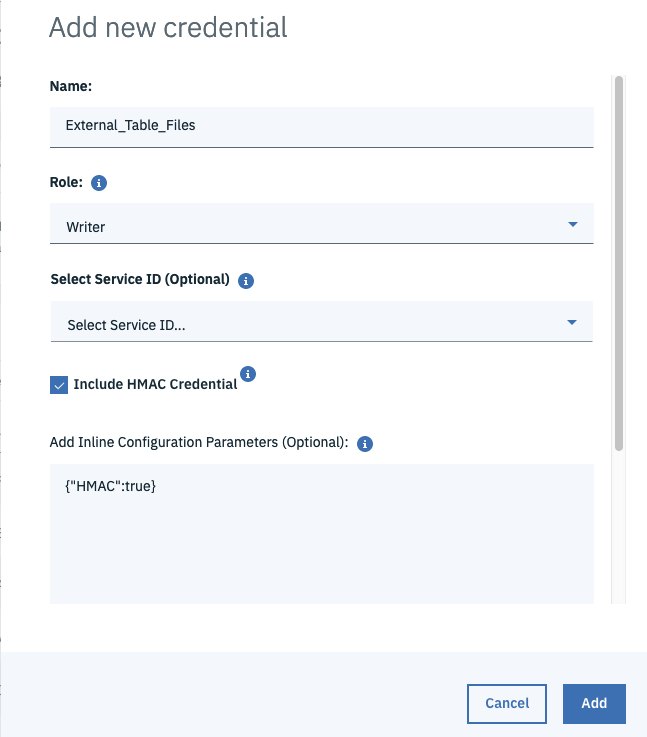
I then opened the credential and here is the top part of the file displayed. You should see something similar.
{
"apikey": "6t-iRb8lvlqtdh8dGY6LrDRYqfLCk3HlzrF5HJZp3D3f",
"cos_hmac_keys": {
"access_key_id": "99b77f8a0c6f47f09658dd1cf0187deb",
"secret_access_key": "3522e1666e319b6b42aed090294a0abf47611e2b8b55dc91"
},
"endpoints": "https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints",
The accessIey_id and secret_access_key values under the cos_hmac_keys are the values you need to create two of fields in the USING clause of the create external table as you can see here. I’ve color coded them for your convenience. The last value needs to be the bucket name you created earlier.
USING (dataobject 'HOSPITAL_READMISSION_LOAD.csv'
s3('s3.us-south.cloud-object-storage.appdomain.cloud',
'99b77f8a0c6f47f09658dd1cf0187deb',
'3522e1666e319b6b42aed090294a0abf47611e2b8b55dc91',
'external-table-cloud-bucket')
At this point you still need the end point (above in gray). You get this by boing back to the buckets window (click Buckets in the left menu above Service credentials), then clicking your bucket name (external-table-cloud-bucket) and then choosing the “Configuration” link on the left and scrolling down to endpoints. Choose the Public end point.
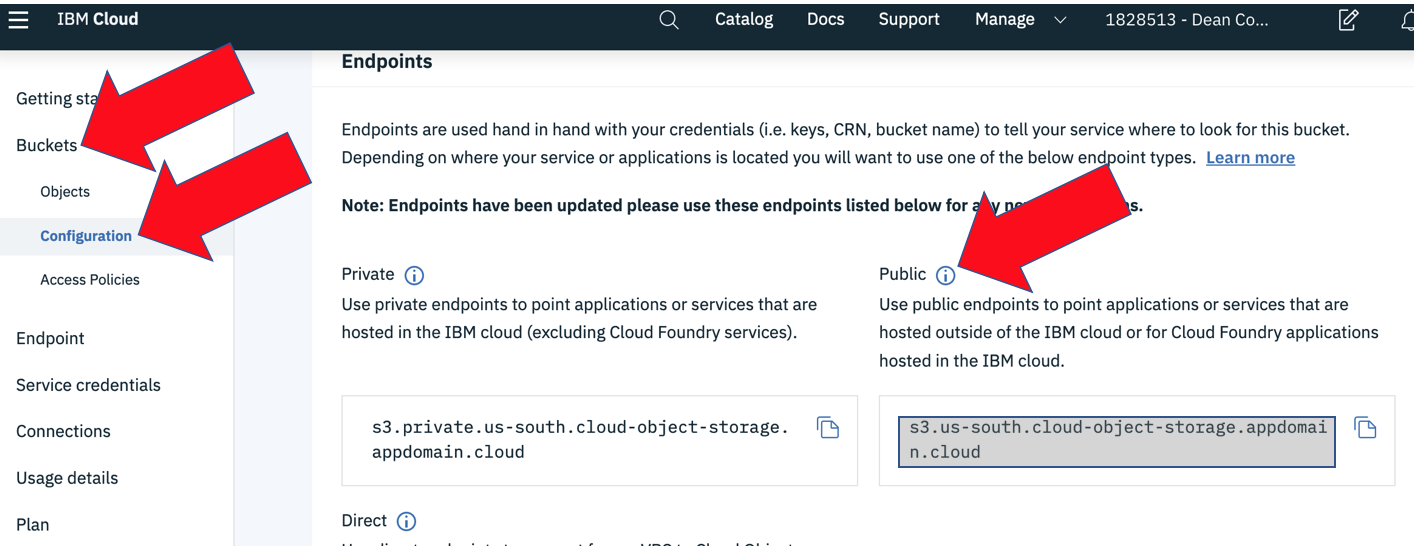
Other than that, creating the external table is pretty much like I discussed in my previous article introducing external tables. In my upcoming examples I’ll use a csv file with hospital readmissions data that I found on medicare.gov. Here is the table that I created with the above USING clause:
CREATE EXTERNAL TABLE DEAN.HOSPITAL_READMISSION_EXT
(HOSPITAL_NAME VARCHAR(200) ,
PROVIDER_NUMBER INTEGER ,
STATE VARCHAR(4) ,
MEASURE_NAME VARCHAR(30) ,
NUMBER_OF_DISCHARGES INTEGER,
FOOTNOTE VARCHAR(4) ,
EXCESS_READMISSION_RATIO DECIMAL(20,4),
PREDICTED_READMISSION_RATE DECIMAL(20,4),
EXPECTED_READMISSION_RATE DECIMAL(20,4),
NUMBER_OF_READMISSIONS INTEGER ,
START_DATE DATE ,
END_DATE DATE)
USING (dataobject 'HOSPITAL_READMISSION_LOAD.csv'
s3('s3.us-south.cloud-object-storage.appdomain.cloud',
'99b77f8a0c6f47f09658dd1cf0187deb',
'3522e1666e319b6b42aed090294a0abf47611e2b8b55dc91',
'external-table-cloud-bucket')
maxerrors 100000
DELIMITER ','
DATEDELIM '-'
Y2BASE 2000
DATESTYLE 'DMONY2'
-- MAXROWS 200
STRING_DELIMITER DOUBLE
SKIPROWS 1
FILLRECORD True
)
;
I would like to point out a few things about the example above that I didn’t discuss in the previous external tables article.
· The hospital readmissions file has column names in the first record so I use the SKIPROWS parameter to skip one row when querying the table.
· Some of the string columns have a comma imbedded in them. Before I set the STRING_DELIMITER parameter to DOUBLE, Db2 thought the comma separated two columns in the field and would skew the positions of all following columns messing up the data types. Since the strings in the file have double quotes around them, I was able to fix the problem with this setting.
· Setting FILLRECORD to “True” allow me to have more fields in the file than columns in the table.
· I used the MAXROWS in testing to limit the number of rows processed for faster query times.
· The data format used in the file was DD-MMM-YY so I used the DATEDELIM, Y2BASE and DATESTYLE parameters as shown.
At this point I can run pretty much any query I like on this table. While it is likely to be slower than querying data in local tablespaces, I have taken zero space on my database server and I did not need to load the data. The create external table command runs quickly and I can start queries right away. This is quite convenient if I’m creating the external table to load data into a permanent table or other temporary use. In my example I want to put some of the data into a column organized (BLU) table for fast queries. Here is one way I could create my permanent column organized table and load data into it. :
CREATE TABLE dean.HOSPITAL_READMISSION
(HOSPITAL_NAME VARCHAR(200) ,
PROVIDER_NUMBER INTEGER ,
MEASURE_NAME VARCHAR(30) ,
PREDICTED_READMISSION_RATE DECIMAL(20,4),
START_DATE DATE)
ORGANIZE BY COLUMN
;
call sysproc.admin_cmd('load from (select HOSPITAL_NAME,
PROVIDER_NUMBER ,
MEASURE_NAME ,
CAST(PREDICTED_READMISSION_RATE AS DECIMAL(20,4)) ,
START_DATE
from dean.hospital_readmission_ext order by start_date)
of cursor messages on server
replace resetdictionary
into dean.HOSPITAL_READMISSION (HOSPITAL_NAME ,
PROVIDER_NUMBER ,
MEASURE_NAME ,
PREDICTED_READMISSION_RATE ,
START_DATE)
');
There are a few things I feel are important to point about the above load command.
· The LOAD utility will frequently build the best compression dictionary when initially loading a table if you have a large amount of data. This will frequently give better performance for column organized tables and compressed row organized tables. So, I used it here.
· An insert into with select could be used instead of the load command and may be an easier choice when the amount of data is small or you are doing a subsequent load.
· I call it using the admin_cmd built-in stored procedure. This allows you to run the load command from any client including the console of Db2 Warehouse on Cloud or the new Data Manager Console. With this procedure you do NOT need to ssh into the database server.
· For some reason the load command needs to have decimal columns cast as decimal when there are null values. Hence, you will notice that the decimal column is select with the cast function: CAST(PREDICTED_READMISSION_RATE AS DECIMAL(20,4)). That was something new I learned while writing this article.
· Whether using an insert or load to put data into a local table, doing it with SQL as shown here allows for a lot of flexibility in column ordering, changing data types, column names, etc.
There were a lot of records with junk in the numeric fields (integer, decimal). The really interesting thing is that using the load command, most of that bad data is just ignored as the external table is read. This makes it really convenient to load a file when there’s lots of bad data in it, if you are OK just ignoring rows with bad data. The problems are noted in a log file and the ignored records are copied to a “bad” file. Here is what my bucket looked like after running the above load command:
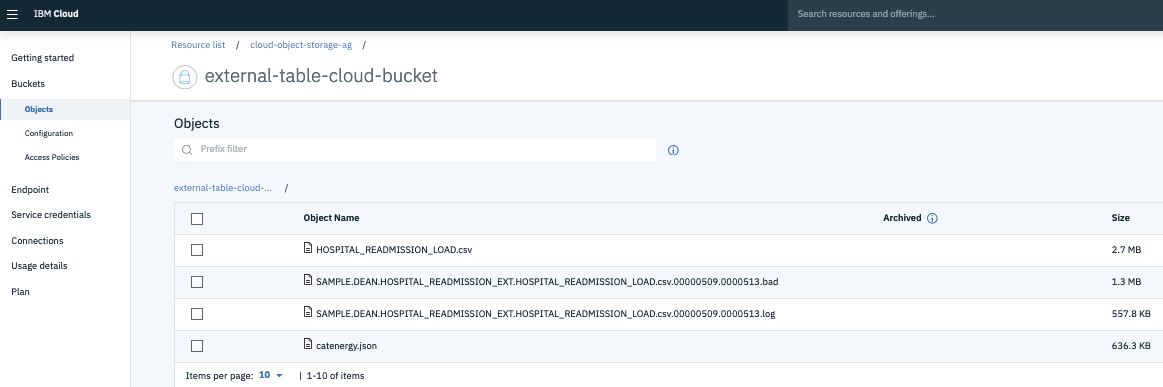
The HOSPITAL_READMISSION_LOAD.csv and catenergy.json are the files I uploaded for my examples, but the two starting with SAMPLE were created by Db2 when running the load command. So it was quite easy to review the errors in the log and see the bad records in the “bad” file. There were about 8100 bad records in my input file, so new table that I loaded had about 8100 fewer rows than the file had records. Using the bad file, I could have fixed the bad records and tried again if that was useful. Note that every time you query an external table you will get at least the log file and possibly the bad file, so be mindful of filling your storage.
While delimited files work great with external tables as we have seen above, you can use external tables to get other file formats into Db2. They will just need to go into one column. Since Db2 provides functions to work with JSON files I use that format for my following examples. First let’s get the data into Db2 by creating an external table on the file in the cloud:
CREATE EXTERNAL TABLE dean.energy_json_ext
(JSON_FIELD clob(2000))
USING (dataobject 'catenergy.json'
s3('s3.us-south.cloud-object-storage.appdomain.cloud',
'99b77f8a0c6f47f09658dd1cf0187deb',
'3522e1666e319b6b42aed090294a0abf47611e2b8b55dc91',
'external-table-cloud-bucket')
maxerrors 100000
DELIMITER '|'
);
Note that I created the external table with one CLOB column since JSON is character data and I want to allow very large documents. You would use an appropriate data type depending on the type of data you had. Each row in the table will have one record (document) from the file. Now I can use the data in a Db2 query just as I would have had I loaded the data into a table using other means. If the data happens to be JSON data, I can do all sorts of interesting things with it as I showed in my earlier article called Query JSON in Db2 such as creating a view on the JSON fields. For my following examples I’ll use the same solar energy production data as in that article. Since we have been talking about using external tables to load data, I continue with that theme for JSON data.
The first thing we need is a way to determine if the JSON document contained in a table is valid. If it isn’t Db2 queries will fail, even if just one document in the table is bad. George Baklarz gave us a function to do just that, and you can create it in your database to verify JSON documents. If you create a view as I showed in my previous article, you should use the following function in the view’s where clause so that bad data doesn’t cause it to blow up when you use it. Here is the function:
CREATE OR REPLACE FUNCTION DB2INST1.CHECK_JSON(JSON CLOB)
RETURNS INTEGER
CONTAINS SQL LANGUAGE SQL DETERMINISTIC NO EXTERNAL ACTION
BEGIN
DECLARE RC BOOLEAN;
DECLARE EXIT HANDLER FOR SQLEXCEPTION RETURN(FALSE);
SET RC = JSON_EXISTS(JSON,'$' ERROR ON ERROR);
RETURN(TRUE);
END
Next we’ll create a table to hold the JSON data. In this case we want to populate some columns with data from the JSON document along with storing the document in BSON format for more efficient processing later on. That is why the JSON field now appears as a Binary Large OBject instead of a Character Large Object that was used in the definition of the external table.
CREATE TABLE dean.energy_json
(SEQ INT NOT NULL GENERATED ALWAYS AS IDENTITY,
READING_TS TIMESTAMP NOT NULL WITH DEFAULT,
ENERGY_UNIT VARCHAR(20),
NOON_THROUGH_2_TOTAL DECIMAL(10,1),
JSON_FIELD blob(2000));
Now we’re ready to load the data into a regular table. In this case I’ll use and insert from select instead of LOAD just for some variety.
insert into dean.energy_json
(READING_TS,
ENERGY_UNIT,
NOON_THROUGH_2_TOTAL,
JSON_FIELD)
select JSON_VALUE(json_field, '$.energy.values[0].date' RETURNING TIMESTAMP),
CASE WHEN JSON_VALUE(json_field, '$.energy.unit' RETURNING VARCHAR(20)) = 'Wh' THEN 'WATT HOURS' END,
JSON_VALUE(json_field, '$.energy.values[12].value' RETURNING Decimal(10,1))
+ JSON_VALUE(json_field, '$.energy.values[13].value' RETURNING Decimal(10,1))
+ JSON_VALUE(json_field, '$.energy.values[14].value' RETURNING Decimal(10,1)),
JSON_TO_BSON(JSON_FIELD)
FROM dean.energy_json_ext
WHERE DB2INST1.CHECK_JSON(JSON_FIELD)
;
Here I show a few examples of using some fields from the JSON document to populate relational fields in the table being loaded. You can use just about any Db2 functions to manipulate the data that you stuff into the columns. Here are some of the things I want to point out about this example:
· READING_TS – Gets the date of the first timestamp of the array in the document
· ENERGY_UNIT – Gets the value of “WATT HOURS” when the unit value is “Wh”
· NOON_THROUGH_2_TOTAL – Gets the sum of the production for hours ending at noon, 1:00 PM and 2:00 PM.
· JSON_FIELD – Gets a copy of the entire JSON documented in BSON format.
· Only load data into the row if the JSON document is valid. If you don’t do this, the entire load will fail even if you have just one bad record.
As I hope this article has made clear, the combination of external tables and cloud data sets allows you to do some pretty interesting things. Another thing I wanted to note about this is that you can replace the file under the external table without needing to alter the table, assuming the new file has the same format as the old one. This can be pretty useful if you get a new file every day and just want to add that data to a regular table. In this case you would just overlay the existing file with the new one, and run the load command to add the newest data.
Feel free to copy and paste any of the code you see in this article, but do so at your own risk. I’ve done only limited testing and cannot guarantee that it will not cause you problems. To make things easier to try out, I’ve provided the two input files on a Box.com folder that you can download if you like and run these examples as is, except that you will need to create and use your own credentials. I mostly used a Jupyter Notebook to develop the queries shown here, and I’ve also put that notebook in the folder. I’ve deleted the cloud storage buckets and credentials used in this article.
***
I’m sure that there are many other things that you can do with External Tables and Cloud Files so please add any thoughts you have on the subject to my Facebook Page and share your thoughts about them.